The aim of this workshop is to know what Terraform is, know the basic concepts to deploy a simple project as well as acquire the skills to deploy more complex projects.
What you will learn
- Understand what is terraform
- Know the potential and weakness of terraform
- Create a terraform project and understand the structure
- Define resources and data sources in templates
- Deploy your IaC in the Cloud
- Overall… get the skills to deploy complex projects
Note: Terraform binaries, documentation and additional information are available on the Terraform website https://terraform.io
Terraform is a tool to manage Infrastructure as Code (IaC)1. It is used to create, manage and update infrastructure resources by creating simple text files following the Terraform Configuration Language.
Terraform is an open source tool written in Go destined to write Infrastructure as Code and to deploy resources defined in the code. Code must be written using the `Hashicorp Configuration Language declarative language.
Terraform supports multiple providers to manage/deploy our infrastructure. In this workshop we will focus on AWS provider. However, there is a full list of supported providers on terraform documentation page. It is worth mentioning other providers such as Azure, Google Cloud Platform or OpenStack as other important cloud providers or tools such as Docker or Kubernetes.
1 Infrastructure as code is the process of provisioning and managing cloud resources by writing template files that humans can easily read and machines can process. Features:
- Code is also documentation
- Automatic deployments are not error-prone
- Developers are responsible of the infrastructure
- Facilitate the deployment of the same infrastructure in multiple environments
- It is traceable and ensures integrity
- Fast deployment
Terraform
Advantages
- It supports multiple providers
- It supports a structured file hierarchy, separating variables definitions, variables values, inputs and outputs
- We can drift the current terraform templates against an already deployed infrastructure (for upgrades)
- Configuration can be checked locally without deploying the infrastructure in the cloud
- We can create dependencies among resources
- The terraform command does not need installation and it is supported in multiple OS. It does not have strong requirements
- Syntax does not change among providers: terraform syntax is global for all providers and the only we need to know is the resource names and options to deploy the infrastructure in a different provider
- We can define a deployment role through a profile
- Desired values (which are not necessaryly by default) can be defined in a separate file
- You can use ARM templates inside Terraform
- You can execute a plan (dry-run) before deploying your changes
- You can import existing resources and use data sources to discover existing ones
- You can verify the differences between the target and the existing state
Drawbacks
- It uses a propietary language (Hashicorp Configuration Language)
- There are two versions of Terraform Configuration Language which are not fully compatible (one used for versions equals/older than 0.11 and another one for versions equals/newer than 0.12)
- New resource types in the providers (e.g. AWS) may take some time to be integrated in Terraform
- Terraform is an OpenSource tool and does not have official support
- Deploying the same infrastructure in multiple accounts require multiple deployments (one per account)
- Upgrades of a full system can make the system become unstable in case some resource deployment fails (no automatic rollback is performed)
- Deployment state is saved where the terraform tool has been run (e.g. in a local PC)
- It does not support wait conditions
- Rolling updates for instances in auto-scaling groups are not supported
AWS CloudFormation
AWS CloudFormation provides a common language for you to model and provision AWS and third party application resources in your cloud environment. AWS CloudFormation allows you to use programming languages or a simple text file to model and provision, in an automated and secure manner, all the resources needed for your applications across all regions and accounts. This gives you a single source of truth for your AWS and third party resources.1
Advantages
- It is fully compatible with AWS, i.e. new AWS resources are quickly supported by CloudFormation
- It supports json and yaml formats (“standards”) and there are not (known) compatibility issues in terms of versions
- It is fully documented and supported by AWS
- Resource types/options which are not supported by CloudFormation can be easily deployed by using lambda functions and custom resources (it is the same workaround for all the cases). These lambda functions and custom resources can be defined within the CloudFormation templates
- A stack (deployment instance) can be upgraded via a direct upgrade or via ChangeSet (to control changes). In any case, if something fails, a rollback is performed and the previous stable state is achieved
- We can define StackSets to deploy the same infrastructure in multiple accounts
- The state of CloudFormation is kept in AWS
- We can create nested stacks (we can make one deployment dependent on a global one)
- We can get drifts between newer versions of the CloudFormation templates and the deployed infrastructure (when upgrading)
- We can deploy the infrastructure by using the command-line (by setting the proper environment settings in, for instance, a local PC) or by using the AWS Console
- It is the recommended option for uses who want to deploy only in AWS
- User role and deployment role can be different. We might not have access to certain services the role used for deployment have
- It supports wait conditions to add breakpoints to the templates
- Rolling updates of EC2 instances managed by auto-scaling groups are supported
Drawbacks
- It only supports AWS
- It is not necessarily as well structured as terraform, as variables (parameters), resources and outputs can be in the same template
- Existing resources can not be integrated in CloudFormation, except if they are exported from other Stacks or by specifying them as input parameters
1 source: https://aws.amazon.com/cloudformation/
To be able to proceed to the following steps, we need a set of tools to be installed. Some of them are mandatory to make the development and deployment of Terraform work. However, other tools are optional but recommended to facilitate our work.
- Terraform binary: (Mandatory) Terraform is a binary file which can be downloaded from the terraform downloads section. Simply download it to your PC, extract it and place it in an accessible path.
- AWS Command Line Interface: (Optional) AWS CLI is a tool that let us send requests to AWS API to perform certain actions. Regarding the operating system you use, you can either download the installer and install it or use the
pipinstaller. To get details instructions of how to do this follow the AWS Command Line Interface page. For instance, for Unix OS, you need Python3 and pip to be installed. Then, execute:
$ pip install awscli
- aws-mfa: (Mandatory, if using MFA) This is a script that help us to manage AWS security credentials using MFA. Please, follow the instructions from the pip page. For instance, for Unix OS, you need Python3 and pip to be installed. Then execute:
$ pip install aws-mfa
- Visual Studio Code or Atom (Optional) These are IDEs (Integrated Development Environments) that will help us to code. Both are good for our goal in this workshop. Visual Studio Code can be downloaded from the Visual Studio Code page and Atom can be downloaded from the Atom official page
- Extensions: (Optional) Extensions for the IDE are recommended because they do some actions for us, such as formating the code or autosave changes. Look form
terraformin the extensions/plugins tab/section of your IDE
First of all, we need to set up our environment to later be able to deploy our resources. To do so, we must follow the AWS documentation. We describe below the procedure anyway.
In the IAM Section in the AWS Console, we have to go to users and select the user we want to use for the deployment. We select Security credentials and Create access key (if not previously created). Copy the user access key and secret access key provided.
If you do not find the file
~/.aws/credentialsin the cases below, type:
$ aws configure
and set the default region (e.g. eu-west-1).
Case 1: Unique account for users and services
If you are not using MFA and simply use an account for users and services (which is not recommended), just set the values copied above in an ~/.aws/credentials file:
[default]
aws_access_key_id = YOURACCESSKEYID
aws_secret_access_key = YOURSECRETACCESSKEY
Case 2: AWS Users Account and AWS Services Account separately
If you use MFA and a user account for the IAM users and a service account for the services (and where you want to deploy your services) as shown in the image below…
… you must follow this configuration:
- Install the aws-mfa tool
$ pip install aws-mfa
- Define a profile (e.g. terraform-long-term) and update your ~/.aws/config file by including the profile options.
[profile default]
...
[profile terraform-long-term]
region = eu-west-1
output = json
role_arn = arn:aws:iam::123456789012:role/role_to_be_assumed
source_profile = default
Note that the
source_profileis the profile that gives us permissions to do an assume role. Therefore, we need to define those credentials for it in the~/.aws/configfile.
- Update your credentials file, by creating a tag profile by appending ‘long-term’ to the profile name (replace the values below with the appropriate ones for your case):
[terraform-long-term]
aws_access_key_id = YOURACCESSKEYID
aws_secret_access_key = YOURSECRETACCESSKEY
aws_mfa_device = arn:aws:iam::123456789012:mfa/iam_user
- Run the aws-mfa command to set the credentials with the profile
aws-mfa --profile terraform
This will place the right credentials in the ~/.aws/credentials file. However, note that this credentials will expire and we will need to execute the command below again once they are expired.
Task: Set up your own environment.
A Terraform project might consist of the following templates:
-
main.tf: It is the main template. This is the template which is called, for instance, when a
terraform applyorterraform destroyis executed. It contains the resource definitions and data sources. If modules are defined, it can invoke those modules. -
variables.tf: It contains the variable definitions and, optionally, the default values. These variables will be called from the main file and are global to the folder/module1.
-
terraform.tfvars: Values for the variables defined in the
variables.tf. -
outputs.tf: It contains the outputs variables of the project/module (if any).
-
terraform.tfstate: This is a generated file that contains the state of the deployment. Even if it is generated, its existence is mandatory once we have do the deployment. If it is removed or lost, Terraform will consider that nothing has been deployed and, hence, we would have missed the “connection” with the previously deployed resources.
MAIN: From the list of files above, the only which is mandatory is the
main.tf.
VARIABLES: If the
terraform.tfvarsfile is not created or some variables values (without default values) are not defined there, the missing values will be requested later from the command line.
OUTPUTS:
outputs.tffile will contain only the output variables we want. The name of those variables can be different to the resources created.
MODULES: A project might contain one or more modules placed in a subdirectory. The file structure of a module is identical to the root folder. Consequently, the only mandatory file is the
main.tf. Additionally, the name of the module will be the name of the directory where those files are contained.
1 As we will see, we can also define local variables. However, these local variables will be defined in the main.tf file.
Task: Create a project with the basic directory structure and initialize it with terraform (use
terraform init).
Note: You do not need to create the
modulefolder.
Provider set-up
Case 1: Unique account for users and services
First of all, if you are using a single account for IAM users and services, and you are not using MFA, you just need to set the following configuraion in the main.tf (this is the simplest case, but not recommended):
provider "aws" {
version = "~=2.40"
region = "<region>"
profile = "<profile>"
}
In this case:
- version: it indicates the plugin version for Terraform. It is recommended to set the version to prevent compatibility issues with future versions.
- region: it is the region where the infrastructure will be deployed. We must set a value which is allowed by AWS (follow AWS documentation).
- profile: the profile to be used during the deployment. If this value is not set, the
defaultprofile will be used. However, this might not be definer or, even if so, we might want to use a different one.
Case 2: AWS Users Account and AWS Services Account separately
In AWS it is recommended to use an account for users separated from an account where the services will be deployed.
Additionally, it is recommended to use the MFA. For the MFA, follow the AWS Set up section. For using a service account by assuming a role by a user, you need to set the following configuration:
provider "aws" {
version = "~> 2.40"
region = "<region>"
profile = "<profile>"
assume_role {
role_arn = "<role_to_be_assumed>"
}
}
In this case, the role_to_be_assumed is a role defined in the service account that grant permissions to the user to access to services in the service account.
Initialize the project
The first step before deployment is to initialize the project. This will download the provider plugin and the used modules. To do do this, just type:
$ terraform init
You will need to do this each time you add a module (either local or external).
Prepare the deployment
You can play with different commands to check that your code is prepare and ready for deployment:
- To check that your code is well-formatted, type:
$ terraform fmt
You need this to do this in all your folders (root directory and modules). Otherwise, the formatting check and fix will only apply to the current directory.
- To check that you code is ready for deployment, type:
$ terraform plan
In case of success, it will indicate the changes that will be peformed during the deployment.
In case of an update of your infrastructure, it will show which resources will be created, which ones will be removed and which ones will be updated (following the current state in
terraform.tfstatefile).
Deploy
Now that you have check that everything is ok, you are ready for the deployment.
- Run the
aws-mfatool as indicated in a previous section to set the updated credentials (if applicaable). - Deploy your infrastructure:
$ terraform apply
You will be requested whether you want to actually deploy the infrastructure. Type yes.
To skip the human validation and confirm that you want to (un-)deploy your infrastructure, you can add the
auto-approveoption to theterraform apply.
Task: Try these commands with your (empty) project.
Undeploy
To undeploy your code, just type:
$ terraform destroy
The destruction of services will be based on the
terraform.tfstatefile. If you remove such file, Terraform will not know which services it needs to destroy and, consequently, nothing will be done.
These are the most useful Terraform options:
- init: Initialize a project (mandatory the first time we create the infrastructure and each time we add a module)
- fmt: Format the terraform code by adding the right tabs, spaces, etc.
- validate: Validates the code syntax (not needed if we are using an IDE with the Terraform extension/plugin, as it already performs it)
- plan: Generate and show an execution plan, i.e. perform a dry-run of the deployment (not mandatory as this is implicit in the apply)
- apply: Deploy new infrastructure changes/resources
- destroy: Destroy deployed resources (the opposite to apply)
- import: Import existing resources in Terraform
- version: Show Terraform version (useful to check if new version is present)
- output: Show the deployment output (in case we need to retrieve it in the future)
- providers: Show the providers used for each module (a combination of providers might be used)
- help: Show all the available options
However, find all the options by typing terraform -h
Input variables
Basics
The definition of variables should be done in the variables.tf file.
A variable must/can contain:
-
type: The supported types of variables are:
- basic types:
- string
- number
- bool
- structures
- list(<TYPE>)
- set(<TYPE>)
- map(<TYPE>)
- object({<ATTR NAME> = <TYPE>, … })
- tuple([<TYPE>, …])
- basic types:
-
default value: It is specified with the
defaultclause. It provides a default value if it not specified anywhere else -
description: A description for the variable, i.e. the usage of the variable
-
validation: Rule to validate the value assigned to a variable. It contains:
- condition: Values accepted by the variable. We can use the function can() in case we use regular expressions (function regex), e.g. for a variable name,
can(regex("^sg-", var.name)) - error_message_: The error message displayed in case the value is not accepted.
- condition: Values accepted by the variable. We can use the function can() in case we use regular expressions (function regex), e.g. for a variable name,
Note: Only the type clause is mandatory in the variable definition.
variable "<var_name>" {
type = <type>
description = "<Usage of the variable>"
validation {
condition = <condition the variable value must satisy>
error_message = "<Message to display>"
}
}
Note: Variable validation is in experimental phase. We have to enable this experimental feature in our module or main project:
terraform {
experiments = [variable_validation]
}
Example:
variable "sg_bastion_host_name" {
type = "string"
description = "Security group for the bastion host"
default = "bastion_sg_name"
validation = {
condition = can(regex("!^sg", var.sg_bastion_host))
error_message = "The security group cannot start with the prefix \"sg\""
}
}
Access to variables
The access of a variable can be done from the same directory where the variables.tf file is placed, including the variables.tf file itself. A variable is accessed by using the var.<var_name> syntax1. For instance, for a var named tags and defined in variables.tf we would access to it in the following way:
resource "aws_instance" "bastion_host" {
...
tags = var.tags
}
Values for variables
The values of the variables specified in the variables.tf can be:
- set during the deployment
- set in a file before the deployment
The second one is the most recommended one because:
- We can redeploy our infrastructure with the same values multiple times
- We can track the changes of the variable values in case we need to modify some of them
- We can deploy the same infrastructure with the same values in multiple environments by just changing those which affect to where the deployment will be placed
- Deployment is faster (especially, if we have many variables) and variables values are error-prune.
In general, we use the file
terraform.tfvarsto define the values of variables. However, we can use these other names:
terraform.tfvars.json- any files with names ending with
.auto.tfvars.auto.tfvars.json
The values for the variables in that file can be specified by setting name = value. For instance:
security_group_name = "bastion_name_sg"
Other ways to set variables
- Use environment variables: Variables can be set as environment variables by preceding the
TF_VAR_prefix. For instance:
$ export TF_VAR_security_group_name=bastion_sg_name
- Use the
-varoption when calling theterraformcommand, e.g.
$ terraform apply -var="security_roup_name=bastion_sg_name"
Local variables
We can define local variables in the main.tf file if we do not want to define some values locally. This can be defined in the locals section.
locals {
mylocalvar = "this is a local variable value"
tags = {
Name = "Value"
}
}
To use these local variables, just call it by using the local. prefix. For instance:
resource "aws_instance" "bastion_host" {
...
tags = local.tags
}
Task: Create the following set of variables:
- a set of variables in the
variables.tffile with a default value- a set of variables in the
variables.tffile without a default value- from some of the variables defined above, add values in a file
terraform.tfvars- create a local variable in the
main.tffile
1 In old versions of Terraform (<= 0.11>) variables were referenced within a ${} block, e.g. ${var.variable_name}.
Output variables
Output variables are specified in a file named outputs.tf. The structure of an output variable is as follows:
output "<var_name> {
value = <value_reference>
description = "<description of the output variables>"
depends_on = [
<dependent_resource>
]
}
From the parameters of an output variable, only the
valueis mandatory.
For instance, we can define an output as:
output "bastion_ip" {
value = aws_instance.bastion.public_ip
description = "Public IP of the bastion host"
}
Output variables can be accessed once the infrastructure has been deployed with the output option and, optionally, the variable name. For instance
$ terraform output bastion_ip
50.17.232.209
We can access output values from child modules by referring them with the syntax module.<module_name>.<output_variable>. For instance:
elb_endpoint_url = module.elb.elb_endpoint_url
A resource is an object in the infrastructure. Each resource block is equivalent to one or more objects in the infrastructure.
The resource definition structure is as follows:
resource "<resource_type>" "<resource_name>" {
<parameter> = <parameter_value>
}
- resource: Indicates that the block corresponds to a resource definition.
- <resource_type>: A type of resource as defined in Terraform. Only types specified by Terraform are allowed, and they are dependent on the provider.
- <resource_name>: A name for the resource. Such name can be any string started with a letter or underscore and may only contain letters, digits, underscores and dashes.
- <parameter>: A parameter allowed by the resource type.
- <parameter_value>: A value of the type allowed by the parameter type.
The resource together with the resource_type identify a resource.
In other words, a resource is an instance of a resource type. It is equivalent to Java objects where we have classes and objects
The list of Terraform resource types is available in the Terraform documentation.
For each resource type, Terraform gives us usually an example of how can we build it with some of the options1:
Implicit dependencies
The defined resources are deployed in parallel unless some dependency between them is set. Implicit dependencies are created when a resource uses the value of another resource. For instance, in the image below, the aws_elb_listener has a dependency with aws_elb_target_group because we needs the value of the target group to be create the listener.
Conditions
Sometimes, we need to create resources conditionally, regarding specific parameter values. Conditions are specified through counters within resources:
count = (<condition> ? 1 : 0)
A condition can be anything, such as the length of a variable is not zero, the value of a variable is equals to some value, etc. Following the structure above, if the condition is satisfied, the resource will be created. Otherwise, the resource creation will be skipped. However, we can revert this behavior by either negating the condition or by setting:
count = (<not_condition> ? 1 : 0)
As an example of a resource creation, see the image above (the aws_elb_listener is created if var.elb_cert_id is set).
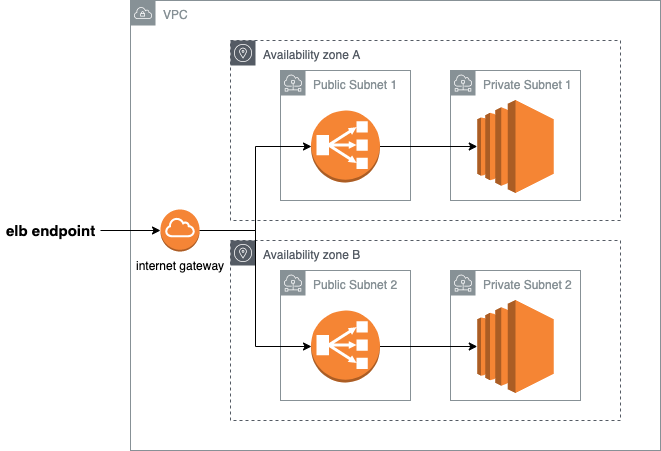
Task: Create the following infrastructure:
Install the
httpdservice, create a sample html page and try to access to it (check security groups if it does not work). We will see in section [data sources](#Adding external files) how to add these actions to automatize the user_data.Clue: To help you with this, find these resources implemented in the https://github.com/ronaldtf/aws-misp project (search in the
vpcandelbmodules).
1 source: https://www.terraform.io/docs/providers/aws/d/s3_bucket.html
A module is a folder with resources that pursue the same goal. For instance, we can create a module for a bastion host (which will contain the EC2 instance, its security group, etc.), a module for an ELB (with the target groups, security groups, etc.).
Apart from the modules you define, Terraform community has a set of modules for AWS which are publicly accessible. Find them here.
A module follows the same structure than the root of the project specified below. It will have an input, a main and an output (as well as the variable values - if needed). It will follow exactly the same rules than the root folder of the project. However, it will be in a subfolder within it.
Treat a module as an isolated subproject within the main Terraform project. The module is isolated from the root project even if the root project will have access to the module output variables.
Module invocation
Assume that we have created a module (named bastion - therefore, in a folder with such name) with a set of input variables:
[variables.tf]
variable bastion_name {
type = string
}
variable bastion_subnet_id {
type = string
}
and a set of output variables:
[outputs.tf]
output bastion_public_ip {
value = aws_instance.bastion.public_ip
}
output bastion_sg {
value = aws_security_group.bastion_sg.id
}
The provider is implicit in a module and will inherit from the root project. However, nothing forbids to specify the own provider in the module either it is the same or a different one from the root project.
To call such module from the root project, in the main.tf file, just write:
module "bastion" {
source = "./bastion"
bastion_name = var.name
bastion_subnet_id = var.bastion_subnet_id
}
(in this case, we have defined variable values in the variables.tf file)
The
sourcepart is mandatory when calling a module. This serves to know where to find the code for the module.
To refer to the output values from the module, we will specify module.<module_name>.<output_variable>
For instance, we can use it as an output of the root project:
[outputs.tf]
variable bastion_ip {
value = module.bastion.bastion_public_ip
description = "Bastion host public IP"
}
Task: Create modules for the example in the previous section and add a bastion host.
Data sources are mechanisms to retrieve data which, in general, does not take part of our infrastructure and needs to be used in our Terraform templates.
Examples of data sources are:
- Retrieve an AMI with specific requirements
- Get AZs in a given region
- Get a snapshot with a given name
- …
The structure of a data source definition is:
data <datasource_type> <datasource_name> {
<parameter_type> = <parameter_value>
}
- data: Key name to indicate that the resource is actually a data source
- <datasource_type>: Type of data source, which must be one of the ones specified in the Terraform documentation.
- <datasource_name>: A custom valid name for the data source
- <parameter_type>: A valid parameter type for the given data source
- <parameter_value>: A value (might be an object) for the given parameter type
Let’s put an example. Imagine we need to retrieve the most recent AMI id for an Ubuntu distro, with HVM virtualization type, EBS as storage volume, and we know that the owner is 099720109477. To do so, we need to create a data source with the following configuration:
data "aws_ami" "ubuntu_ami" {
filter {
name = "name"
values = ["ubuntu*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
filter {
name = "root-device-type"
values = ["ebs"]
}
filter {
name = "state"
values = ["available"]
}
owners = ["099720109477"]
most_recent = true
}
Notes:
- As we can see, a data source for retrieven an AMI id can have multiple filters
- A data source can return a set (list) of elements. If we specify
most_recent = truewe only retrieve the latest one. - We can refer to the value of the data source by calling this way
data.aws_ami.ubuntu_ami.id
Task 1: Retrieve the availability zones for a given region Task 2: Find a way to get the public IP of your host with data sources.
Adding external files
One of the advantages of Terraform against CloudFormation is that it allows invoking external scripts. In general, those scripts are suffixed with the .tpl extension. A typical example is to use those scripts as the user_data in an EC2 instance. For instance, we can define the following file…
[user_data.sh.tpl]
#! /bin/bash
yes | sudo apt-get update
yes | sudo apt-get upgrade
yes | sudo apt-get install squid
… and adding it as a data source:
data "template_file" "user_data" {
template = file("${path.module}/user_data.sh.tpl")
}
We can also pass parameters to a script by specifying the vars clause. For instance (in this case, var.elb_url indicates that it is a variable that comes from the variables.tf file):
data "template_file" "user_data" {
template = file("${path.module}/user_data.sh.tpl")
vars = {
elb = var.elb_url
}
}
We can set the following environment variables for debugging:
- TF_LOG: enables logs to appear on stderr. Allowed values are:
- TRACE (default)
- DEBUG
- INFO
- WARN
- ERROR
- TF_LOG_PATH: It indicates the file where the log is saved.
- TF_INPUT: If set to 0 indicates that interactive mode is not expected. If some values are not set in the configuration files or as input option, the deployment fails.
- TF_CLI_ARGS: Options to pass to the terraform command.
- TF_DATA_DIR: Location where terraform places the working directory data, such as the backend configuration.
- TF_CLI_CONFIG_FILE: Location of the terraform CLI configuration file (for further details, visit the CLI Configuration page).
Task: Set some of these variables, especially
TF_LOGandTF_LOG_PATHand analyze the traces
Now that you know…
- What is Terraform
- What is the robustness and limitations of Terraform
- Differences between Terraform and CloudFormation
- How is the structure of a terraform project
- How to define and deploy resources in AWS (the Cloud)
- Deploy any project
… it’s time to put your hands on new projects and start new challenges!